
A Dual-Stream Neural Network Explains the Functional Segregation of Dorsal and Ventral Visual Pathways in Human Brains
(Choi, Han, Wang, Zhang, Liu, NeurIPS, 2023)
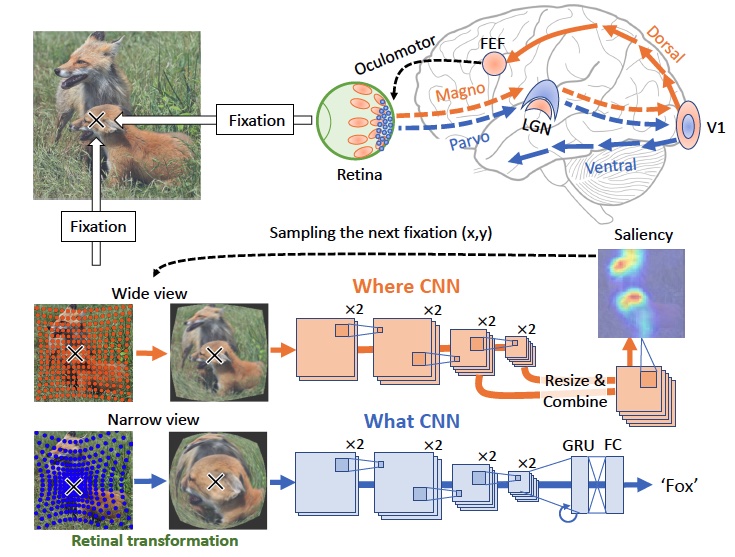
The human visual system uses two parallel pathways for spatial processing and object recognition. In contrast, computer vision systems tend to use a single feedforward pathway, rendering them less robust, adaptive, or efficient than human vision. To bridge this gap, we developed a dual-stream vision model inspired by the human eyes and brain. At the input level, the model samples two complementary visual patterns to mimic how the human eyes use magnocellular and parvocellular retinal ganglion cells to separate retinal inputs to the brain. At the backend, the model processes the separate input patterns through two branches of convolutional neural networks (CNN) to mimic how the human brain uses the dorsal and ventral cortical pathways for parallel visual processing. The first branch (WhereCNN) samples a global view to learn spatial attention and control eye movements. The second branch (WhatCNN) samples a local view to represent the object around the fixation. Over time, the two branches interact recurrently to build a scene representation from moving fixations. When compared to brain responses in humans watching a movie, the WhereCNN and WhatCNN branches matched the dorsal and ventral pathways of the visual cortex, respectively. We also conducted experiments to disentangle the roles of retinal sampling, learning objective, and attention-guided eye movement in the functional alignment between the model and the brain. Results suggest that the functional segregation of the brain’s dorsal and ventral visual pathways is driven primarily by their different learning objectives – spatial attention vs. object recognition, secondarily by the sampling biases of their retinal inputs. This dual-stream model takes a further step in brain-inspired computer vision, enabling parallel neural networks to actively explore and understand the visual surroundings.
Explainable semantic space by grounding language to vision with cross-modal contrastive learning
(Zhang, Choi, Han, Liu, NeurIPS, 2021)

In natural language processing, most models try to learn semantic representations merely from texts. The learned representations encode the “distributional semantics” but fail to connect to any knowledge about the physical world. In contrast, humans learn language by grounding concepts in perception and action and the brain encodes “grounded semantics” for cognition. Inspired by this notion and recent work in vision-language learning, we design a two-stream model for grounding language learning in vision. The model includes a VGG-based visual stream and a Bert-based language stream. The two streams merge into a joint representational space. Through cross-modal contrastive learning, the model first learns to align visual and language representations with the MS COCO dataset. The model further learns to retrieve visual objects with language queries through a cross-modal attention module and to infer the visual relations between the retrieved objects through a bilinear operator with the Visual Genome dataset. After training, the model’s language stream is a stand-alone language model capable of embedding concepts in a visually grounded semantic space. This semantic space manifests principal dimensions explainable with human intuition and neurobiological knowledge. Word embeddings in this semantic space are predictive of human-defined norms of semantic features and are segregated into perceptually distinctive clusters. Furthermore, the visually grounded language model also enables compositional language understanding based on visual knowledge and multimodal image search with queries based on images, texts, or their combinations.
Connecting concepts in the brain by mapping cortical representations of semantic relations
(Zhang, Han, Worth, Liu, 2020. Nature Communications, 11:1877)
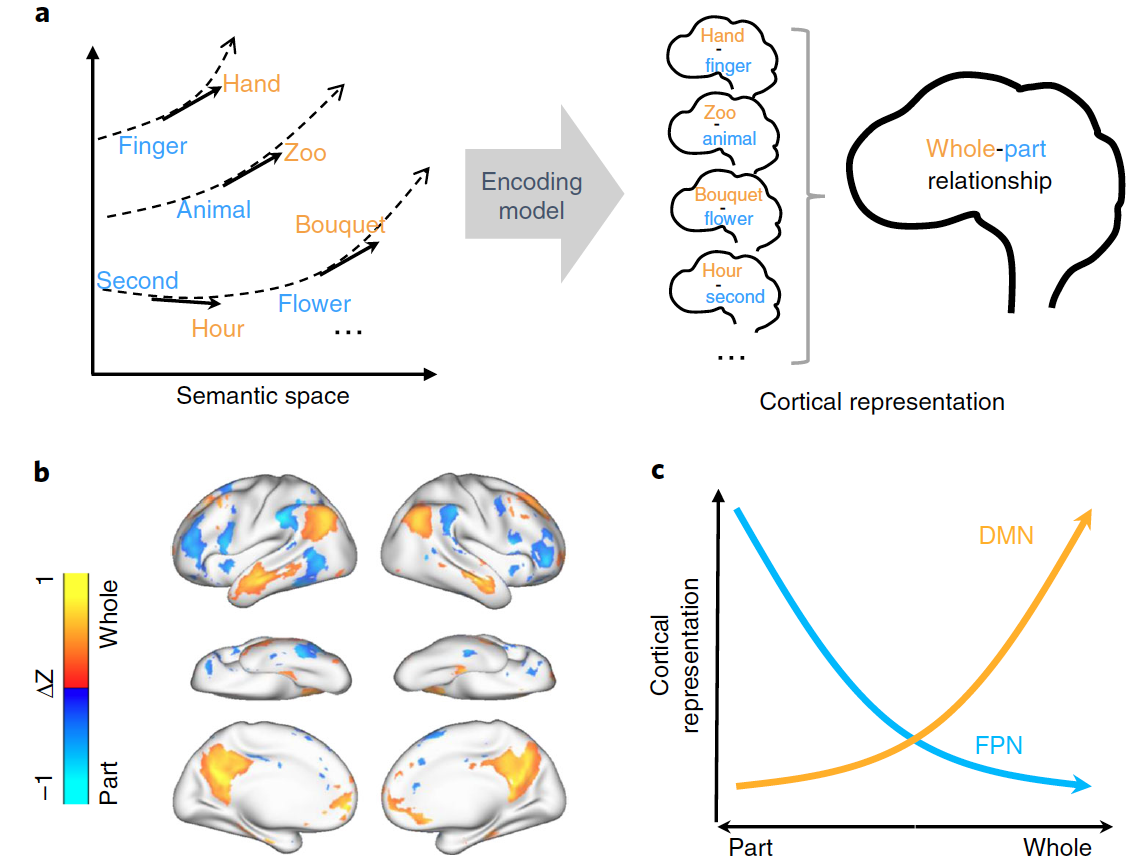
In the brain, the semantic system is thought to store concepts. However, little is known about how it connects different concepts and infers semantic relations. To address this question, we collected hours of functional magnetic resonance imaging data from human subjects listening to natural stories. We developed a predictive model of the voxel-wise response and further applied it to thousands of new words. Our results suggest that both semantic categories and relations are represented by spatially overlapping cortical patterns, instead of anatomically segregated regions. Semantic relations that reflect conceptual progression from concreteness to abstractness are represented by cortical patterns of activation in the default mode network and deactivation in the frontoparietal attention network. We conclude that the human brain uses distributed networks to encode not only concepts but also relationships between concepts. In particular, the default mode network plays a central role in semantic processing for abstraction of concepts.
Deep Predictive Coding Network with Local Recurrent Processing
(Han, Wen, Zhang, Fu, Culurciello, Liu. NeurIPS, 2018)
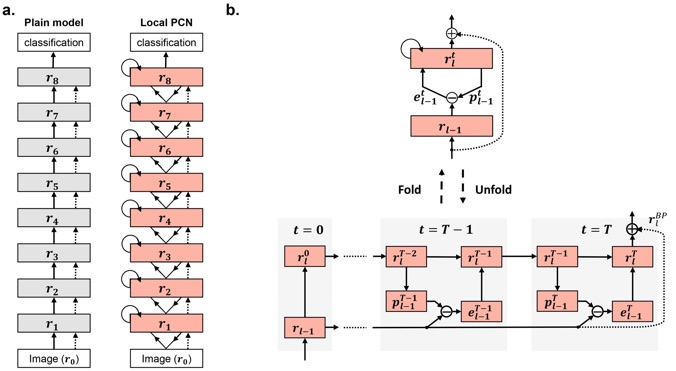
Inspired by “predictive coding” – a theory in neuroscience, we develop a bi-directional and dynamical neural network with local recurrent processing, namely predictive coding network (PCN). Unlike any feedforward-only convolutional neural network, PCN includes both feedback connections, which carry top-down predictions, and feedforward connections, which carry bottom-up errors of prediction. Feedback and feedforward connections enable adjacent layers to interact locally and recurrently to refine representations towards minimization of layer-wise prediction errors. When unfolded over time, the recurrent processing gives rise to an increasingly deeper hierarchy of non-linear transformation, allowing a shallow network to dynamically extend itself into an arbitrarily deep network. We train and test PCN for image classification with SVHN, CIFAR and ImageNet datasets. Despite notably fewer layers and parameters, PCN achieves competitive performance compared to classical and state-of-the-art models. Further analysis shows that the internal representations in PCN converge over time and yield increasingly better accuracy in object recognition. Errors of top-down prediction also map visual saliency or bottom-up attention. This work takes us one step closer to bridging human and machine intelligence in vision.
Deep Predictive Coding Network for Object Recognition
(Wen, Han, Shi, Zhang, Culurciello, Liu. ICML, 2018)
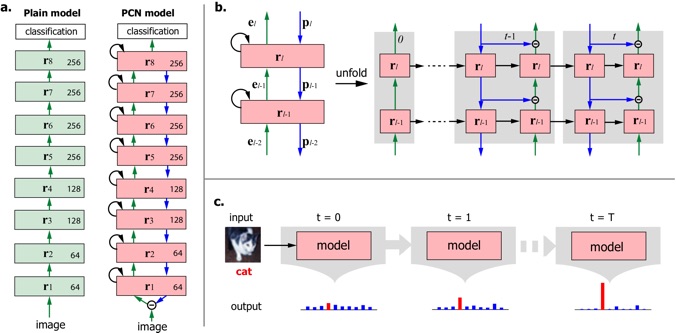
Inspired by predictive coding in neuroscience, we designed a bi-directional and recurrent neural net, namely deep predictive coding networks (PCN). It uses convolutional layers in both feedforward and feedback networks, and recurrent connections within each layer. Feedback connections from a higher layer carry the prediction of its lower-layer representation; feedforward connections carry the prediction errors to its higher-layer. Given image input, PCN runs recursive cycles of bottom-up and top-down computation to update its internal representations to reduce the difference between bottom-up input and top-down prediction at every layer. After multiple cycles of recursive updating, the representation is used for image classification. In training, the classification error backpropagates across layers and in time. With benchmark data (CIFAR-10/100, SVHN, and MNIST), PCN was found to always outperform its feedforward-only counterpart: a model without any mechanism for recurrent dynamics, and its performance tended to improve given more cycles of computation over time. In short, PCN reuses a single architecture to recursively run bottom-up and top-down process, enabling an increasingly longer cascade of non-linear transformation. For image classification, PCN refines its representation over time towards more accurate and definitive recognition.
Variational auto-encoder: an unsupervised model for encoding and decoding fMRI activity in visual cortex
(Han, Wen, Shi, Lu, Zhang, Di, Liu, NeuroImage, 2019)
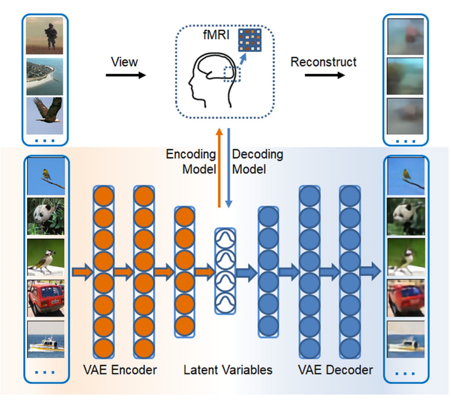
Goal-driven and feedforward-only convolutional neural networks (CNN) have been shown to be able to predict and decode cortical responses to natural images or videos. Here, we explored an alternative deep neural network, variational auto-encoder (VAE), as a computational model of the visual cortex. We trained a VAE with a five-layer encoder and a five-layer decoder to learn visual representations from a diverse set of unlabeled images. Inspired by the “free-energy” principle in neuroscience, we modeled the brain’s bottom-up and top-down pathways using the VAE’s encoder and decoder, respectively. Following such conceptual relationships, we used VAE to predict or decode cortical activity observed with functional magnetic resonance imaging (fMRI) from three human subjects passively watching natural videos. Compared to CNN, VAE resulted in relatively lower accuracies for predicting the fMRI responses to the video stimuli, especially for higher-order ventral visual areas. However, VAE offered a more convenient strategy for decoding the fMRI activity to reconstruct the video input, by first converting the fMRI activity to the VAE’s latent variables, and then converting the latent variables to the reconstructed video frames through the VAE’s decoder. This strategy was more advantageous than alternative decoding methods, e.g. partial least square regression, by reconstructing both the spatial structure and color of the visual input. Findings from this study support the notion that the brain, at least in part, bears a generative model of the visual world.
Deep recurrent neural net reveals a hierarchy of process memory
(Shi, Wen, Zhang, Han, Liu. Human Brain Mapping, 2018)
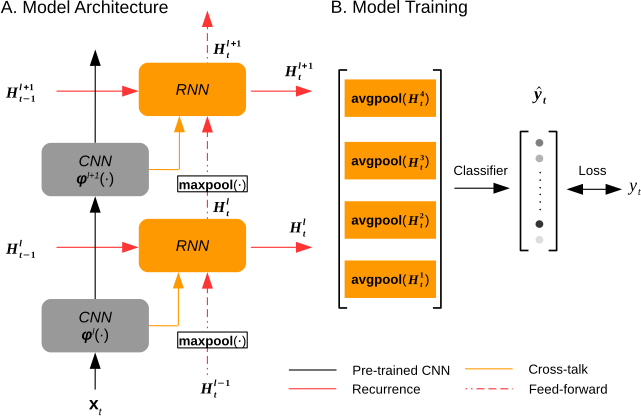
The human visual cortex extracts both spatial and temporal visual features to support perception and guide behavior. Deep convolutional neural networks (CNNs) provide a computational framework to model cortical representation and organization for spatial visual processing, but unable to explain how the brain processes temporal information. To overcome this limitation, we extended a CNN by adding recurrent connections to different layers of the CNN to allow spatial representations to be remembered and accumulated over time. The extended model, or the recurrent neural network (RNN), embodied a hierarchical and distributed model of process memory as an integral part of visual processing. Unlike the CNN, the RNN learned spatiotemporal features from videos to enable action recognition. The RNN better predicted cortical responses to natural movie stimuli than the CNN, at all visual areas especially those along the dorsal stream. As a fully-observable model of visual processing, the RNN also revealed a cortical hierarchy of temporal receptive window, dynamics of process memory, and spatiotemporal representations. These results support the hypothesis of process memory, and demonstrate the potential of using the RNN for in-depth computational understanding of dynamic natural vision.
Deep residual networks reveals a nested hierarchy of cortical category representation.
Wen, Shi, Chen, Liu. NeuroImage (2018)
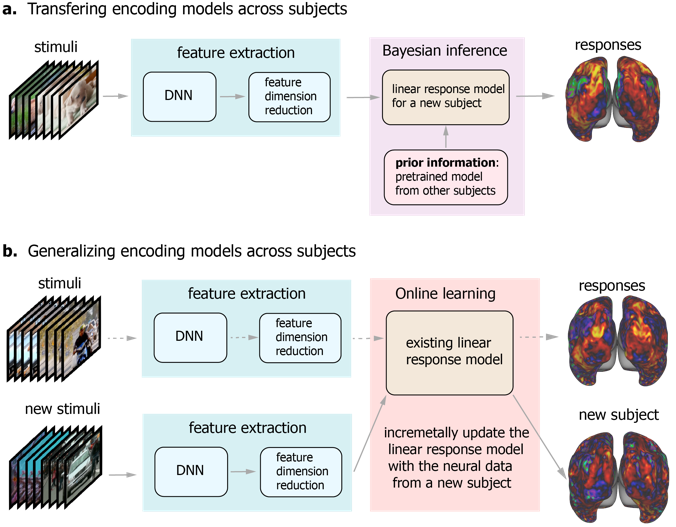
Recent studies have shown the value of using deep learning models for mapping and characterizing how the brain represents and organizes information for natural vision. However, modeling the relationship between deep learning models and the brain (or encoding models), requires measuring cortical responses to large and diverse sets of natural visual stimuli from single subjects. This requirement limits prior studies to few subjects, making it difficult to generalize findings across subjects or for a population. In this study, we developed new methods to transfer and generalize encoding models across subjects. To train encoding models specific to a subject, the models trained for other subjects were used as the prior models and were refined efficiently using Bayesian inference with a limited amount of data from the specific subject. To train encoding models for a population, the models were progressively trained and updated with incremental data from different subjects. For the proof of principle, we applied these methods to functional magnetic resonance imaging (fMRI) data from three subjects watching tens of hours of naturalistic videos, while deep residual neural network driven by image recognition was used to model the visual cortical processing. Results demonstrate that the methods developed herein provide an efficient and effective strategy to establish subject-specific or population-wide predictive models of cortical representations of high-dimensional and hierarchical visual features.
Deep residual network predicts cortical representation and organization of visual features for rapid categorization.
(Wen, Shi, Chen, Liu. Scientific Reports (2018))
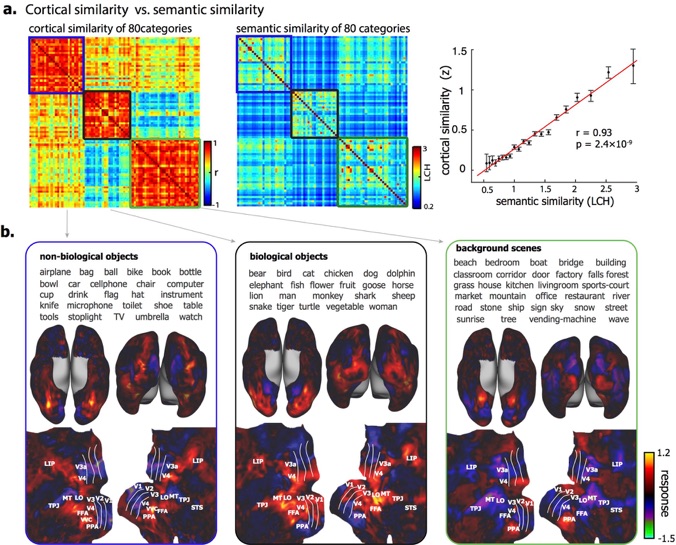
The brain represents visual objects with topographic cortical patterns. To address how distributed visual representations enable object categorization, we established predictive encoding models based on a deep residual neural network, and trained them to predict cortical responses to natural movies. Using this predictive model, we mapped human cortical representations to 64,000 visual objects from 80 categories with high throughput and accuracy. Such representations covered both the ventral and dorsal pathways, reflected multiple levels of object features, and preserved semantic relationships between categories. In the entire visual cortex, object representations were modularly organized into three categories: biological objects, non-biological objects, and background scenes. In a finer scale specific to each module, object representations revealed sub-modules for further categorization. These findings suggest that increasingly more specific category is represented by cortical patterns in progressively finer spatial scales. Such a nested hierarchy may be a fundamental principle for the brain to categorize visual objects with various levels of specificity, and can be explained and differentiated by object features at different levels.
Neural encoding and decoding with deep learning during dynamic natural vision
(Wen, Shi, Zhang, Lu, Cao, Liu. Cerebral Cortex (2017) doi: 10.1093/cercor/bhx268)
Convolutional neural network (CNN) driven by image recognition has been shown to be able to explain cortical responses to static pictures at ventral-stream areas. Here, we further showed that such CNN could reliably predict and decode functional magnetic resonance imaging data from humans watching natural movies, despite its lack of any mechanism to account for temporal dynamics or feedback processing. Using separate data, encoding and decoding models were developed and evaluated for describing the bi-directional relationships between the CNN and the brain. Through the encoding models, the CNN-predicted areas covered not only the ventral stream, but also the dorsal stream, albeit to a lesser degree; single-voxel response was visualized as the specific pixel pattern that drove the response, revealing the distinct representation of individual cortical location; cortical activation was synthesized from natural images with high-throughput to map category representation, contrast, and selectivity. Through the decoding models, fMRI signals were directly decoded to estimate the feature representations in both visual and semantic spaces, for direct visual reconstruction and semantic categorization, respectively. These results corroborate, generalize, and extend previous findings, and highlight the value of using deep learning, as an all-in-one model of the visual cortex, to understand and decode natural vision.